|
I obtained my PhD degree from University of Amsterdam (UvA), advised by Prof. Cees Snoek and Dr. Hazel Doughty. |

|
|
|
|
|
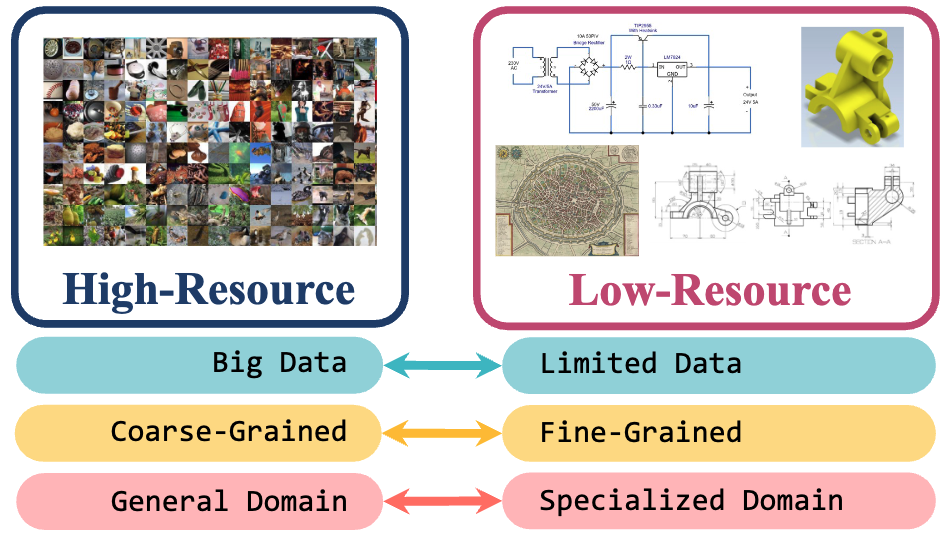
Yunhua Zhang, Hazel Doughty, Cees G.M. Snoek CVPR, 2024 arXiv / Website / Code Low-resource settings are well-established in natural language processing, where many languages lack sufficient data for machine learning at scale. However, low-resource problems are under-explored in computer vision. In this paper, we strive to address this gap and explore the challenges of low-resource image tasks with vision foundation models. |
|
|
Yunhua Zhang, Hazel Doughty, Cees G.M. Snoek NeurIPS, 2023 arXiv Multimodal learning assumes all modality combinations of interest are available during training to learn cross-modal correspondences. In this paper, we challenge this modality-complete assumption for multimodal learning and instead strive for generalization to unseen modality combinations during inference. |
|
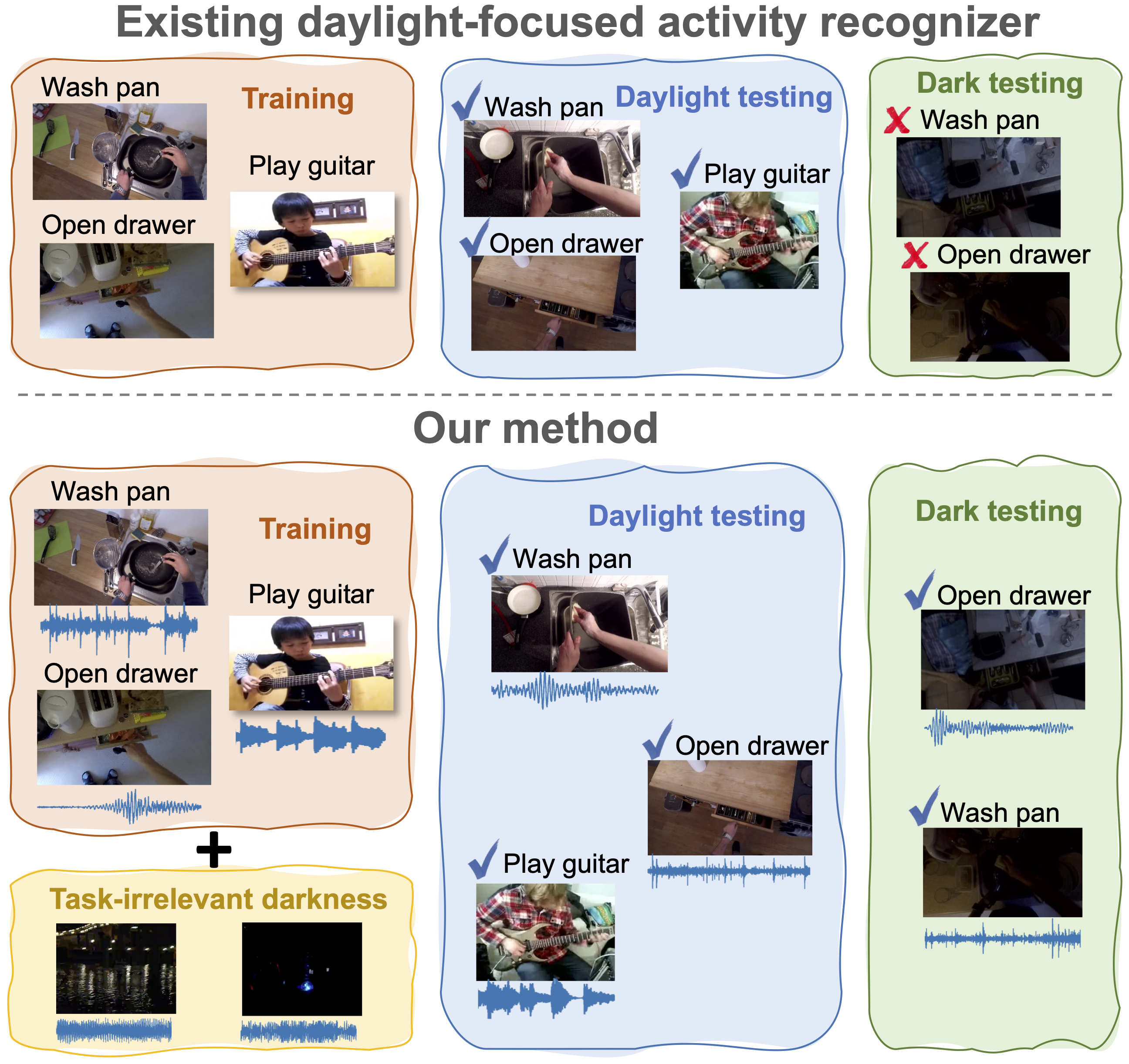
Yunhua Zhang, Hazel Doughty, Cees G.M. Snoek IJCV, 2024 arXiv State-of-the-art activity recognizers are effective during the day, but not trustworthy in the dark. The main causes are the distribution shift from the lower color contrast as well as the limited availability of labeled dark videos. Our goal is to recognize activities in the dark as well as in the day. |

|
Yunhua Zhang, Hazel Doughty, Ling Shao, Cees G.M. Snoek CVPR, 2022 bibtex / arXiv / code & data / website / demo video / CVPR presentation 2nd place in the UDA track, EPIC-Kitchens Challenge @CVPR 2022. This paper strives for activity recognition under domain shift, for example caused by change of scenery or camera viewpoint. Different from vision-focused works we leverage activity sounds for domain adaptation as they have less variance across domains and can reliably indicate which activities are not happening. |
|
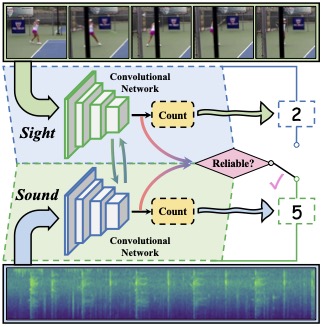
Yunhua Zhang, Ling Shao, Cees G.M. Snoek CVPR, 2021 bibtex / arXiv / demo video / CVPR presentation / code & data Also presented at EPIC Workshop@CVPR 2021 and Sight and Sound Workshop@CVPR 2021 We incorporate for the first time the corresponding sound into the repetition counting process. This benefits accuracy in challenging vision conditions such as occlusion, dramatic camera view changes, low resolution, etc. |
|
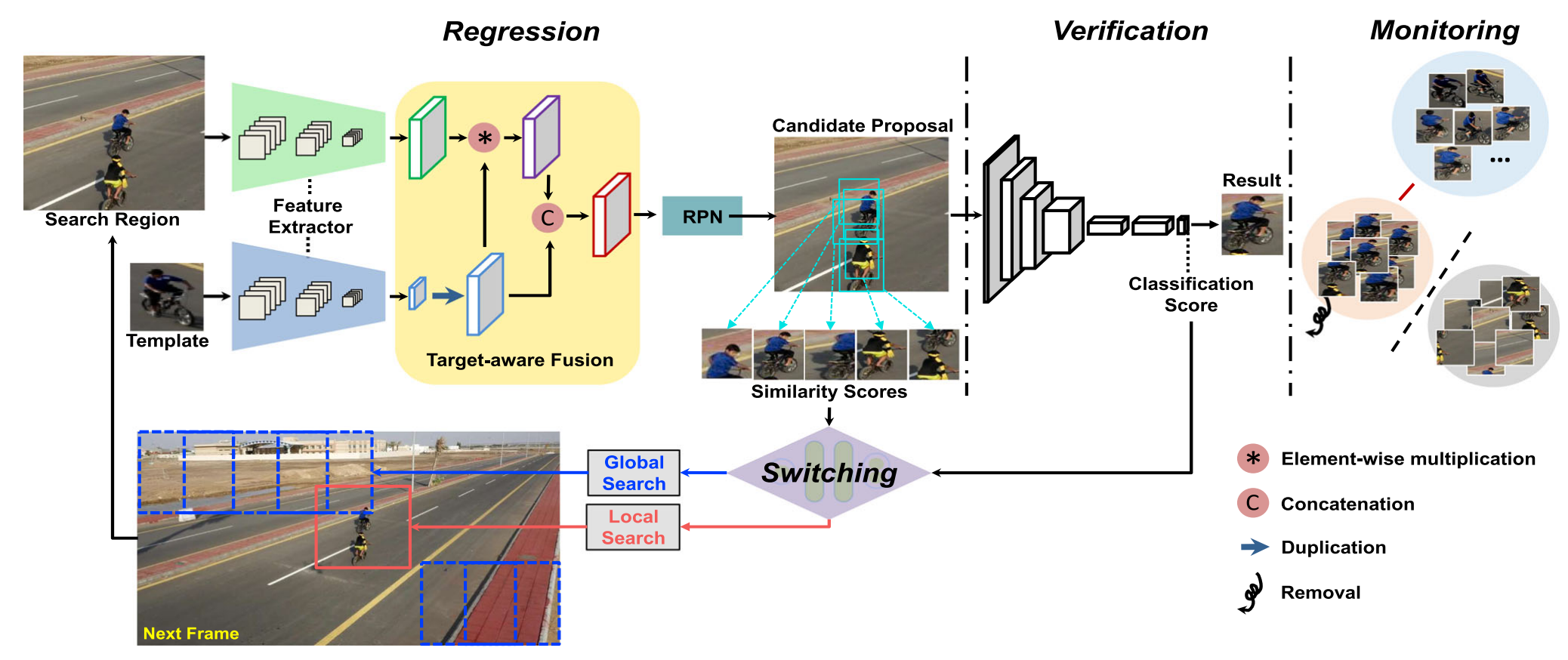
Yunhua Zhang, Lijun Wang, Dong Wang, Jinqing Qi, Huchuan Lu IJCV, 2021 bibtex / PDF / code This paper proposes a new visual tracking algorithm, which leverages the merits of both template matching approaches and classification models for long-term object detection and tracking. |
|
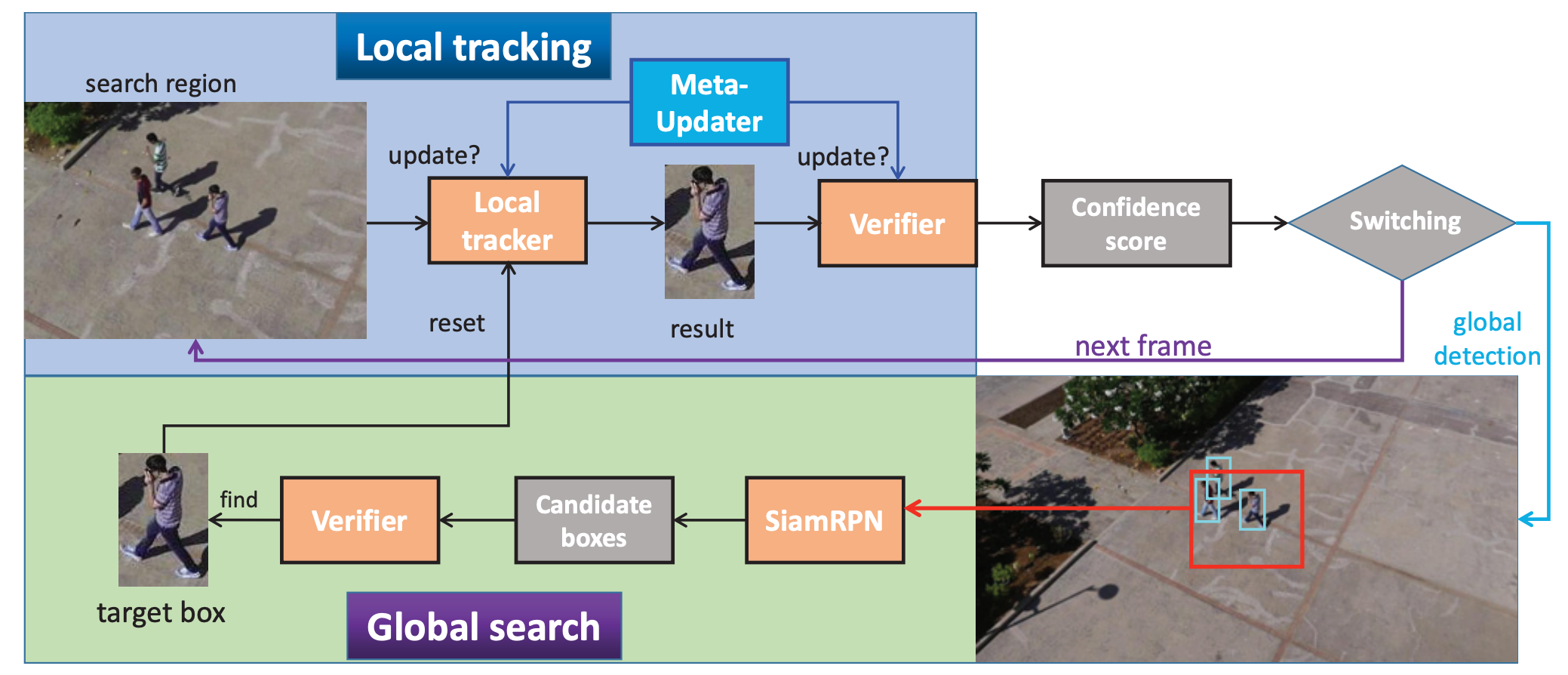
Kenan Dai, Yunhua Zhang, Dong Wang, Jianhua Li, Huchuan Lu, Xiaoyun Yang CVPR, 2020 (Best Paper Award Nominee) bibtex / PDF / code In this work, we propose a novel offline-trained Meta-Updater to address an important but unsolved problem: Is the tracker ready for updating in the current frame? |
|
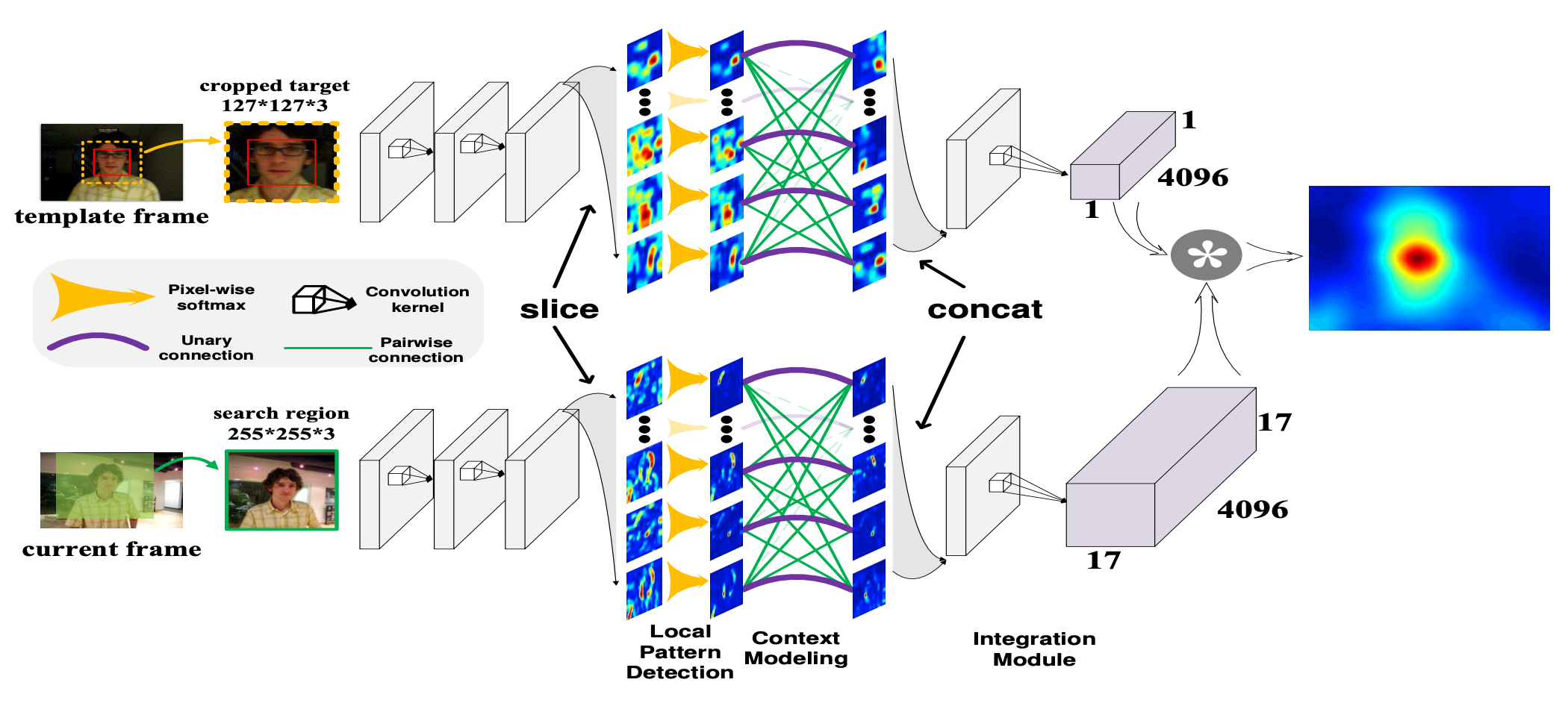
Yunhua Zhang, Lijun Wang, Jinqing Qi, Dong Wang, Mengyang Feng, Huchuan Lu ECCV, 2018 bibtex / PDF In this paper, we propose a local structure learning method, which simultaneously considers the local patterns of the target and their structural relationships for more accurate target tracking. |
|
|
 |
The winning track of VOT2019 Long-term Tracking Challenge
Kenan Dai, Yunhua Zhang, Jianhua Li, Dong Wang, Xiaoyun Yang, Huchuan Lu ICCV Workshop, 2019 Report / Code The winning track of VOT2018 Long-term Tracking Challenge Yunhua Zhang, Lijun Wang, Dong Wang, JinQing Qi, Huchuan Lu ECCV Workshop, 2018 Report / Code |
|
This website uses the template provided by Jon Barron. |