
| We recognize activities under domain shifts, caused by change of scenery, camera viewpoint or actor, with the aid of sound. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| We recognize activities under domain shifts, caused by change of scenery, camera viewpoint or actor, with the aid of sound. |
| This paper strives for activity recognition under domain shift, for example caused by change of scenery or camera viewpoint. The leading approaches reduce the shift in activity appearance by adversarial training and self-supervised learning. Different from these vision-focused works we leverage activity sounds for domain adaptation as they have less variance across domains and can reliably indicate which activities are not happening. We propose an audio-adaptive encoder and associated learning methods that discriminatively adjust the visual feature representation as well as addressing shifts in the semantic distribution. To further eliminate domain-specific features and include domain-invariant activity sounds for recognition, an audio-infused recognizer is proposed, which effectively models the cross-modal interaction across domains. We also introduce the new task of actor shift, with a corresponding audio-visual dataset, to challenge our method with situations where the activity appearance changes dramatically. Experiments on this dataset, EPIC-Kitchens and CharadesEgo show the effectiveness of our approach. For instance, we achieve a 5% absolute improvement over previous works in EPIC-Kitchens. |
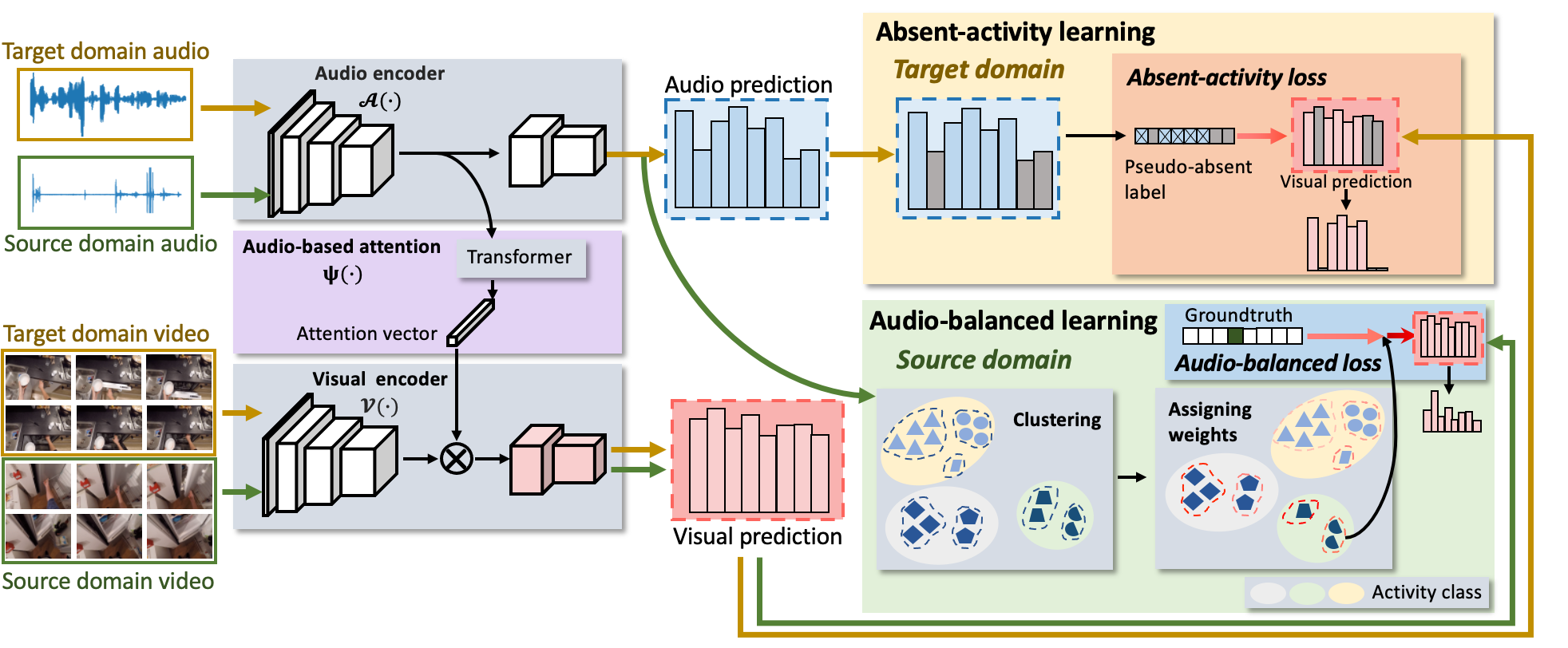
| We train our audio-adaptive model in two stages using videos from source and target domains with accompanying audio. In the first stage we train our audio-adaptive encoder that uses audio to adapt a visual encoder to be more robust to distribution shifts. In the second stage, we train our audio-infused recognizer using pseudo-labels from the audio-adaptive encoder for the target domain and the ground-truth labels for the source domain. The audio-infused recognizer maps the source and target domains into a common space and fuses audio and visual features to produce an activity prediction for either domain |
|
| Audio-adaptive encoder for activity recognition under domain shift |
| Our audio-adaptive encoder consists of a visual encoder, an audio encoder and an audio-based attention module. Since the sounds of activities have less variance across domains, the encoder aims to extract visual features that are invariant but discriminative under domain shift with the aid of the audio encoder pretrained for audio-based activity recognition. To this end, we train the visual encoder and the attention module with two audio-adaptive learning methods: absent-activity learning or unlabeled target data and audio-balanced learning for labeled source data. The former aims to remove irrelevant parts of the visual features while the latter helps to handle the differing label distribution between domains. Once trained, for each video, we can extract an audio feature vector from the audio encoder and a series of visual features from the visual encoder with which to train our audio-infused recognizer |
|
|
| Audio-infused recognizer. |
| While audio can help focus on the activity-relevant visual features inside our audio-adaptive encoder, there is still a large difference between the appearance of activities in different domains. To further eliminate domain-specific visual features and fuse the activity cues from the audio and visual modalities, we propose the audio-infused recognizer. As shown in the above figure, we add domain embedding to encourage a common visual representation across domains. Then, an audio-adaptive class token is obtained from a series of activity sound feature vectors, considering both audio and visual features. It is sent into the transformer together with the visual features. By the transformer’s self attention, this token aggregates information from visual features with the domain-invariant audio activity cues for activity classification. |
| We introduce ActorShift, where the domain shift comes from the change in actor species: we use humans in the source domain and animals in the target domain. This causes large variances in the appearance and motion of activities. For the corresponding dataset we select 1,305 videos of 7 human activity classes from Kinetics-700 as the source domain: sleeping, watching tv, eating, drinking, swimming, running and opening a door. For the target domain we collect 200 videos from YouTube of animals performing the same activities. We divide them into 35 videos for training (5 per class) and 165 for evaluation. The target domain data is scarce, meaning there is the additional challenge of adapting to the target domain with few unlabeled examples. |

|
| Examples in our ActorShift dataset |
 |
Yunhua Zhang, Hazel Doughty, Ling Shao, Cees G.M. Snoek Audio-Adaptive Activity Recognition Across Video Domains In CVPR, 2022. (hosted on ArXiv) [Bibtex] |
|
|
|
|
AcknowledgementsThis website template was originally made by Phillip Isola and Richard Zhang for a colorful ECCV project; the code can be found here. |